
大数据挖掘与云服务模式
随着物联网、移动通信、移动互联网和数据自动采集技术的飞速发展以及在各行各业的广泛应用,人类社会所拥有的数据面临着前所未有的爆炸式增长。美国互联网数据中心指出,互联网上的数据每年以50%的速度增长,每两年翻一番,而目前世界上90%以上的数据是最近几年才产生的,人类社会进入了“大数据”时代。因此,信息的获取非常重要,一定程度上,信息的拥有量已经成为决定和制约社会发展的重要因素。
数据是人类社会的宝贵财富,当前以及未来的许多经济、社会和科学问题需要依赖于对数据的分析和挖掘才能解决,社会的发展对数据的依赖将越来越高。飞速增长的大数据给经济发展和科学技术进步带来了新的机遇,同时也给当前的信息技术带来巨大挑战。由于要挖掘的信息源中的数据都是海量的,而且以指数级增长,传统的集中式串行数据挖掘方法不再是一种适当的信息获取方式。因此必须对传统数据挖掘进行理论、方法和算法上创新,特别是创新大数据计算环境下的数据挖掘理论、方法与技术,以满足大数据挖掘的应用需求。更进一步,扩展数据挖掘算法处理大规模数据的能力,并提高运行速度和执行效率,成为一个不可忽视的问题。大数据挖掘的主流方式是基于云计算的大数据挖掘云服务模式。
基于大规模数据处理平台Hadoop,我们研究开发了面向海量结构化数据的并行挖掘云服务平台COMS,以及面向海量Web数据的并行挖掘云服务平台WMCS,其目的是设计实现并行数据挖掘算法处理大数据集,且提高执行效率。更重要是,这两个系统把数据挖掘作为一种服务提供给用户,用户不用了解具体的数据挖掘算法,也不用了解数据挖掘的整个流程,只需要把挖掘任务和数据提交到我们的系统中,系统就会进行挖掘计算,把挖掘结果返回给用户。该数据挖掘云服务模式具有广泛的应用前景,适用于拥有数据但没有数据挖掘研发能力的企业。
大数据的关键技术是数据挖掘
我们认为应在大数据挖掘算法与技术方面开展如下研究:
(1)探索大数据的分布规律和复杂性度量,研究并掌握与数据分布相结合的样本抽样技术,以及与大数据学习任务目标相一致的属性选择技术,提出大数据挖掘算法的分布式逼近理论,为研究和设计精简、高效的大数据处理策略和数据挖掘算法提供理论指导。
(2)研究分布式并行计算环境下的大数据挖掘的基本策略,实现与数据分布相联系的大数据分治策略以及与算法机理相结合的算法并行策略。
(3)在大数据挖掘算法的复杂度分析与误差估计基础上,研究降低复杂度精度可控的新的数据挖掘算法,提出并实现高效的大数据分类、聚类、关联分析、异常发现等四类算法,对具有低复杂度、高并行度、精度有保证的实用算法实现并行化。
(4)研究大数据中共性的增量学习、迁移学习、多任务多视图学习方法和相应的高效算法,设计和实现大数据挖掘算法。
(5)大数据挖掘云服务平台研发。在上述理论与方法研究基础上,开发实现大数据挖掘云服务平台,支持数据规模从TB级到PB级动态增长,且具有扩展性的数据挖掘云服务应用。
总之,大数据问题是目前学术界和产业界共同关注的挑战性问题。伴随着大数据的采集、传输、处理和应用的相关技术就是大数据处理技术,是系统使用非传统的工具来对大量的结构化、半结构化和非结构化数据进行挖掘处理。从而获得分析和预测结果的一系列数据挖掘技术。
大数据挖掘的主流方式
数据挖掘软件发展的历程,结合其他资料可以划分成五代,到现在基于云计算的并行数据挖掘方式,应该算作第五代,如表1所示。
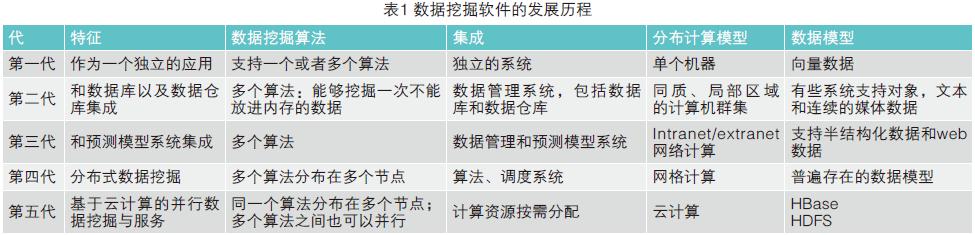
第一代只是单独算法,单个系统,单个机器,而且是向量数据。第二代已经和数据库结合起来,有多个算法。第三代则是跟预测模型集成起来,而且它支持Web数据、半结构化的数据,应该说这种情况是一种网络化计算。第四代是分布式数据挖掘,是在2000年到2005年左右所做的一件事情,基本上是基于网格计算的概念来做多个算法,分布在多个节点上的方式。第五代,即现在基于云计算的并行数据挖掘与服务的模式,同一个算法可以分布在多个节点上,多个算法之间是并行的,多个资源实行按需分配,而且分布式计算模型采用云计算模式,数据存储采用分布式存储HDFS/HBase等。
大数据挖掘为什么以云计算为主流计算模式?云计算给软件带来的变革表现在软件即服务上。部署软件不再是单机安装软件,而是在云计算平台上部署,用户只需通过网络浏览器就可以接受云服务,而且云计算平台可以自主按需调配资源满足用户的计算需求,这使得中小企业可以不进行硬件投资,只在公共云计算平台上使用云服务软件即可;也可以在利用企业原有设备或者在硬件开支不大的情况下部署云计算平台,从而完成原来小型机才能完成的计算任务,实现高性能、低成本的计算,这就是云计算给信息领域带来的变革。云计算模式保证分布式并行数据挖掘和高效实时挖掘。云服务模式保证挖掘技术的共享,降低数据挖掘应用门槛,普惠各个行业。企业租用云服务进行数据挖掘,不必开发软件,也不必部署云计算平台。当然这有一个前提:就是云服务要相当完备,能够做到招之即来、挥之即去。目前,还达不到所有服务都能在云上找到的地步,但是随着云计算的发展,公共需求将会日益得到满足。另外利用现有设备搭建自己的云计算平台,也将是方便、实用、成本低廉的一种安排,从而为满足中小企业个性化的数据处理需求提供保障。
已有的研究表明:大数据挖掘的主流方式是基于云计算的大数据挖掘模式。基于云计算的大数据挖掘要为千千万万的不同规模的企业应用,就必须借助互联网提供大数据挖掘云服务,这种服务使得企业可以方便地定制提交数据挖掘任务,快捷而直接使用数据挖掘能力,不必关心数据挖掘具体执行者,挖掘出数据的潜在价值,获得业务模式优化的策略,为决策提供支持,进而提高利润和效益。
大数据挖掘云服务平台解决方案
基于大规模数据处理平台Hadoop以及并行编程模式Map/Reduce,我们研究开发了面向海量结构化数据的并行挖掘云服务平台COMS,以及面向海量Web数据的并行挖掘云服务平台WMCS。
COMS
COMS是2010年在PDMiner基础之上开发的并行数据挖掘云服务系统。PDMiner是由中国科学院计算所机器学习与数据挖掘课题组在2008年底开发完成的中国最早的基于云计算平台的并行数据挖掘系统。该系统已经用于中国移动TB级实际数据的挖掘;达到了商用软件的精度,做到了高性能、低成本的海量数据挖掘。该项技术现已用于电信、国家电网、信息安全等领域。
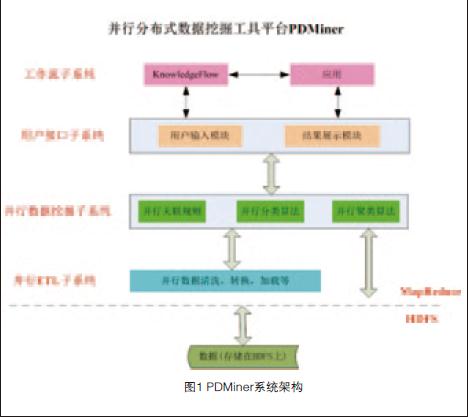
PDMiner系统架构如图1所示,主要包含前台用户接口、后台数据挖掘子系统两大部分。其中后台数据挖掘子系统又主要分为预处理模块分类算法模块,聚类算法模块和关联规则算法模块。该系统基于Hadoop云计算平台,使用分布式文件系统HDFS存储数据,开发并行算法与数据预处理操作超30种。该系统部署在中国移动“大云”平台上,稳定运行在256个节点组成的Linux集群下,具有高可扩展性。多个工作流任务可以在云计算环境下的任意节点同时启动,互不干扰,具有高容错能力。该系统提供了一系列并行挖掘算法和ETL操作组件,开发的并行ETL算法达到了线性加速比,可实现TB级海量数据的预处理及之后的并行挖掘分析处理,且挖掘算法效率随着节点数增加而线性上升。以消耗计算资源较为突出的聚类应用为例,现有的商用数据挖掘系统只能支持100万用户一个月之内数据的知识发现,这距离实际要求相差甚远。传统方式处理1TB的数据挖掘需要8小时,而使用16个节点的云计算平台则只需要40分钟,且成本仅为传统方式的四分之一。
在中国电子学会吴基传、李德毅主编的云计算权威报告《云计算技术发展报告》(2012年)中这样写道:“中国科服学院计算技术研究所的机器学习与数据挖掘研究团队受中国移动委托于2008年底研究开发出基于云计算平台的并行数据挖掘系统,并且部署在“大云”平台上,支持电信网络和运营支撑的海量数据挖掘和分析,如客户分群、客户流失预测、客户欺诈识别、客户价值分析等。开发出中国最早的用于实际TB级数据挖掘的基于云计算平台的数据挖掘工具平台系统。开发出的系统已经用于实际数据的挖掘,性能指标达到了预期要求。达到了商用软件的精度、数据处理规模远远超出目前商用软件。该系统具有通用性,还可以用于金融、税务、证券、电力等行业,具有广泛、重大产业应用前景,会产生重大的经济效益和社会效益。”
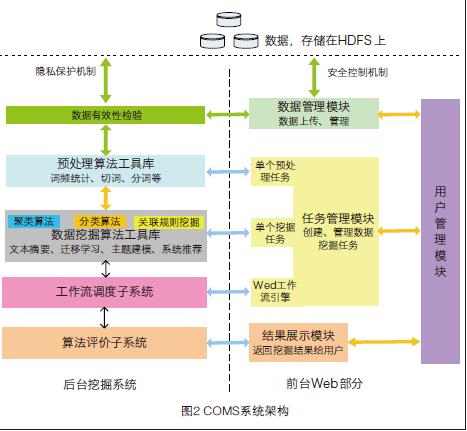
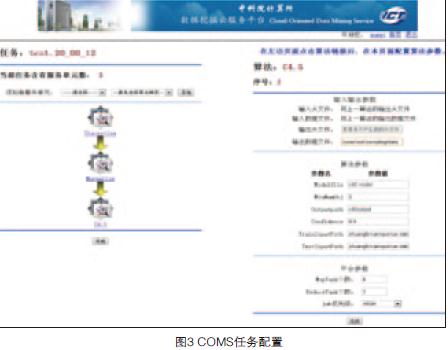
图2和图3分别给出了COMS系统架构和任务配置主界面。该系统通过网络对注册用户提供多种个性化的基于云计算的数据挖掘服务,通过数据管理和任务管理模块,用户可以对数据和个性化挖掘任务进行配置和管理,享受安全的并行数据挖掘云服务。该系统将数据挖掘算法和相应预处理操作公开化,强调用户自主、个性化的特性,通过云让用户自主定制需要的数据挖掘任务,达到分析数据的目的。注册用户可以通过用户管理模块管理私有数据、配置挖掘任务以及查看结果展示。前台部分均通过Web界面与用户交互。当任务配置完毕后,启动挖掘任务,后台挖掘系统接收指令调度相应算法模块,访问用户数据进行分析,最终反馈挖掘结果给系统前台部分。
WMCS
WMCS是2013年在CWMS基础上开发完成的基于云计算的Web挖掘云服务平台。
CWMS系统架构如图4所示,包括信息采集子系统、文本处理与建模子系统、文本挖掘子系统以及用户接口子系统。该系统已经用于数据通讯行业的文本挖掘实际任务。该系统设计结构复杂,模块繁多,功能强大,共包含逾40种挖掘算法与预处理操作。其中,文本挖掘子系统包括全文检索、文本分类、文本关联、情感分析、语义分析、文本聚类、文档摘要、主题发现和实体识别共9大类,20种并行算法。系统中每一个模块均可独立运行,实现了高聚合低耦合的设计理念,同时便于进行代码维护以及二次开发。
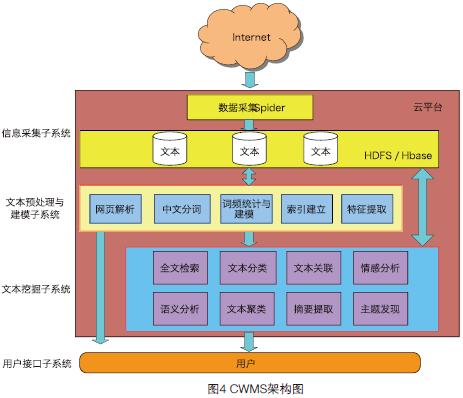
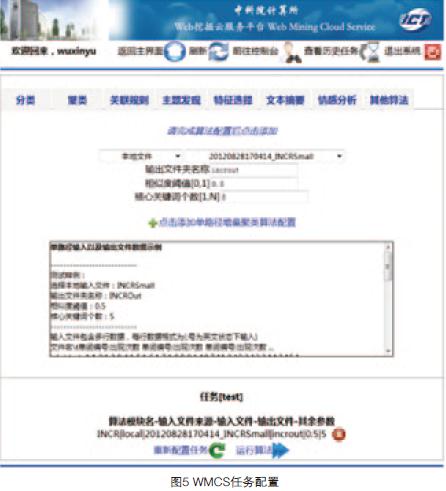
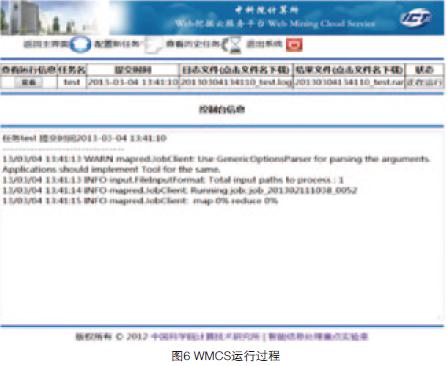
WMCS云服务平台面向互联网中的文本数据,提供基于云的从数据采集到数据处理再到文本挖掘的一站式服务。图5和图6分别给出了任务配置以及系统运行过程情况。该云服务平台通过网络对注册用户提供多种个性化的基于云计算的文本挖掘服务,通过数据管理和任务管理模块,用户可以对数据和个性化挖掘任务进行配置和管理,享受安全的并行文本挖掘云服务。该系统将文本挖掘算法和相应预处理操作公开化,强调用户自主、个性化的特性,通过云让用户自主定制需要的数据挖掘任务,达到分析数据的目的。目前,该系统共上线17种文本挖掘算法,开创了Web文本挖掘云服务的先河。
作者单位:中国科学院计算技术研究所智能信息处理重点实验室




版权:《高科技与产业化》编辑部版权所有 京ICP备12041800号 地址:北京市海淀区中关村北四环西路33号 邮编:100080 联系电话:(010)82626611-6618 传真:(010)82627674 联系邮箱:hitech@mail.las.ac.cn |